Extracting Text from Images: A Guide Using Python Techniques
Written on
Chapter 1: Understanding OCR
Optical Character Recognition (OCR) has transitioned from being a complex aspect of artificial intelligence to a straightforward task that can be performed on your personal computer.
The image below illustrates the text I aimed to extract:

Chapter 2: Simple Text Extraction Without Code
One of the simplest methods to achieve text extraction involves no programming skills at all and can be done quickly via Google Docs.
To begin, upload your image file to Google Docs. After that, right-click on the image and choose Open with -> Google Docs.
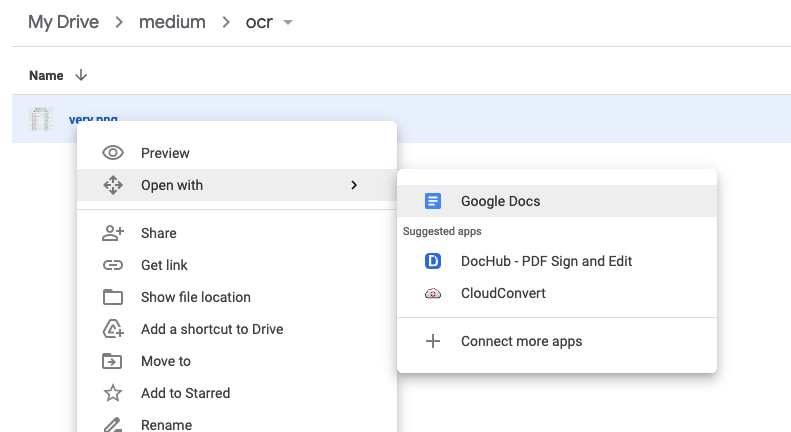
This action will generate a two-page document: one page displays the image, while the other contains the converted text.

However, the extracted text may not always be easily readable.
Time to Write Some Code
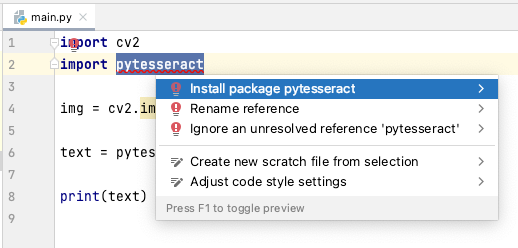
To refine the extraction process, I opened PyCharm (you can download the community edition here) and inserted the necessary code. Initially, I encountered some missing components, specifically cv2 and pytesseract, which were highlighted in red.
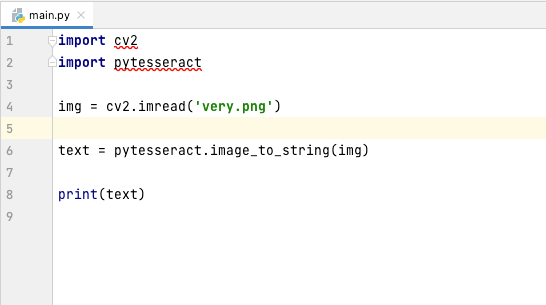
A quick right-click on the highlighted imports allows you to address these issues.
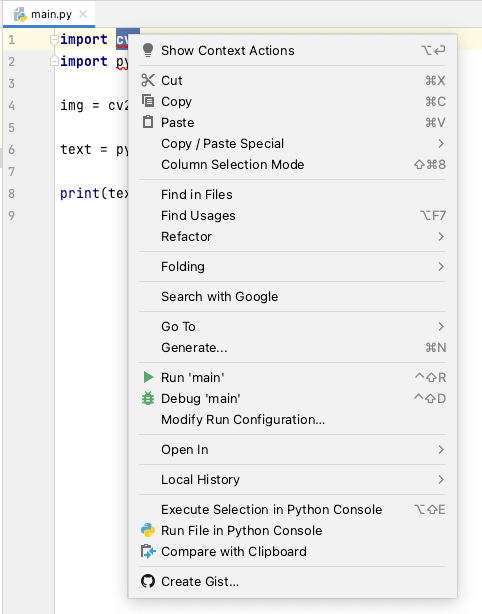
Select Show Context Actions -> Install package opencv-python.
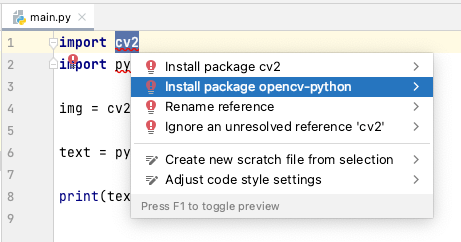
Similarly, install pytesseract.
Once the installation is complete, run the application, and the output will be as follows:
WORDS TO USE
Instead of “very,” consider these alternatives:
- very noisy → deafening
- very often → frequently
- very old → ancient
- very old-fashioned → archaic
- very open → transparent
- very painful → excruciating
- very pale → ashen
- very perfect → flawless
- very poor → destitute
- very powerful → compelling
- very pretty → beautiful
- very quick → rapid
- very quiet → hushed
- very rainy → pouring
- very rich → wealthy
- very sad → sorrowful
- very scared → petrified
- very scary → chilling
- very serious → grave
- very sharp → keen
- very shiny → gleaming
- very short → brief
- very shy → timid
- very simple → basic
Overall, the output is quite decent, but further refinement can enhance the clarity and formatting by removing extraneous characters.
Final Clean Output
The final cleaned-up output is as follows:
- deafening = very noisy
- frequently = very often
- ancient = very old
- archaic = very old-fashioned
- transparent = very open
- excruciating = very painful
- ashen = very pale
- flawless = very perfect
- destitute = very poor
- compelling = very powerful
- beautiful = very pretty
- rapid = very quick
- hushed = very quiet
- pouring = very rainy
- wealthy = very rich
- sorrowful = very sad
- petrified = very scared
- chilling = very scary
- grave = very serious
- keen = very sharp
- gleaming = very shiny
- brief = very short
- timid = very shy
- basic = very simple
If you found this article helpful, feel free to hit the "clap" button below! You can press and hold it to give a standing ovation of up to 50 claps.

For more engaging content, consider signing up for Medium—it's free, simple, and quick!

Chapter 3: Video Tutorials
To deepen your understanding, check out the following video tutorials:
This tutorial, titled "How to Extract Text From Your Images in ONLY 3 Lines of Code | Python Tutorial," provides a concise guide to text extraction using Python.
Another helpful video is "How to convert image to text using python," which further explores the topic.