Optimizing Business Locations with Location Analytics
Written on
Chapter 1: Understanding Location Analytics
Location analytics harnesses data to identify the ideal locations for business operations. This practice employs data-centric methodologies to assess and enhance geographical placements, aiding businesses in making educated choices on asset locations, such as kiosks or retail stores, to maximize customer engagement and operational effectiveness.

I am deeply enthusiastic about the transformative potential of data in the business world. Utilizing data to tackle complex challenges and unveil valuable insights is a passion of mine. Recently, I interviewed for a Business Analyst position with a company that primarily profits from kiosks that facilitate payments for various service providers, including banks and telecom firms. During the interview, I was probed about location insights, which sparked my curiosity.
After reflecting for a few days, I delved into this subject further. Consider the possibility that the company might ask for the optimal site for a new kiosk. What would be my approach to determining this? How can we leverage location data to boost revenue? Are there established methodologies to address this type of inquiry? These questions are quite intriguing, don’t you think?
Remember, data analytics revolves around conceptualizing ideas and validating them. To achieve success, it is essential to adopt a business perspective, comprehend customer needs, and pose the right inquiries. I intend to continue exploring practical examples to uncover answers.
Imagine being a Business Analyst at ‘Million,’ tasked with identifying the best new location for a kiosk terminal. My approach involves a 'divide and conquer' strategy:
- Collect competitor location data.
- Compile potential site coordinates for the new terminal.
- Clean and analyze the data.
- Evaluate various methodologies.
- Choose the most effective approach.
Initially, I gathered the locations of competitor branches and terminals as well as potential sites such as supermarkets for our kiosks. While I won't delve into data scraping here, those interested in that aspect can check out this repository: Data Extraction.
Next, I categorized and cleaned the data into three groups: competitors, prospective locations for new kiosks, and existing terminals operated by my company.
Section 1.1: Mathematical Approaches to Location Selection
Now, let’s examine the mathematical strategies and solutions I identified during my research that can be applied to this scenario.
Subsection 1.1.1: Facility Location Problem (FLP)
The Facility Location Problem (FLP) focuses on identifying optimal sites for facilities (like kiosks) to reduce costs while ensuring efficient service for the maximum number of individuals. For instance, if you aim to establish three new kiosks in a city, FLP would help determine the ideal locations based on where the majority of people live and work, all while minimizing expenses related to distance and competition.
Subsection 1.1.2: Voronoi Diagrams
Voronoi Diagrams partition a space into regions, ensuring that each point within a region is closest to a particular location (like a kiosk). This prevents overlapping service areas. If there are multiple kiosks within a city, employing a Voronoi Diagram can illustrate the coverage areas for each kiosk, allowing identification of underserved locations or areas with excessive kiosk proximity.
Subsection 1.1.3: Gravity Model
The Gravity Model estimates the frequency of usage of a location based on its proximity to individuals and other points of interest, such as shopping centers or public transport. For example, if you are considering a kiosk near a busy supermarket and a bus station, the Gravity Model can assist in predicting customer foot traffic based on accessibility.
However, these mathematical methodologies often require data that may not be readily available or could be expensive to obtain. Therefore, we adopt a customized approach for this task.
Subsection 1.1.4: Weighted Scoring Models
A Weighted Scoring Model is a decision-making instrument that prioritizes options by assigning varying levels of importance (weights) to different factors. In our scenario, we can evaluate potential kiosk sites based on their distance from competitors and proximity to key locations (like supermarkets).
Each factor receives a weight according to its significance to the business strategy, allowing for a ranking of locations based on these weighted considerations.
Consider three potential locations for a new kiosk:
- Location A: Moderately distanced from competitors and close to a supermarket.
- Location B: Significantly distanced from competitors and somewhat near a supermarket.
- Location C: Close to competitors yet adjacent to a high-traffic supermarket.
You score each location based on these criteria:
- Location A: Competitors (7/10), Supermarket (9/10)
- Location B: Competitors (9/10), Supermarket (7/10)
- Location C: Competitors (4/10), Supermarket (8/10)
Using weighted scores:
- Location A: (7 * 0.6) + (9 * 0.4) = 7.8
- Location B: (9 * 0.6) + (7 * 0.4) = 8.2
- Location C: (4 * 0.6) + (8 * 0.4) = 5.6
In this instance, Location B emerges as the preferred choice, offering an optimal balance between competitor distance and proximity to potential customer locations like supermarkets.
Now that we have a fitting approach, especially for small datasets and time constraints, let’s begin analyzing our dataset.
The first video titled "Location Analytics | Analyze Location Data on Maps" illustrates the methods and tools for analyzing geographic data to optimize business locations.
The second video titled "What is Location Intelligence?" provides insights into the concept of location intelligence and its relevance in business decision-making.
Section 1.2: Analyzing the Dataset
Now, let's proceed with the analysis of our dataset.
import pandas as pd
# Load the combined CSV file
df = pd.read_csv('data/data.csv')
# Display the first few rows of the dataframe to understand its structure
df.head()
Distribution Analysis
# Analyze the distribution of locations by type
location_distribution = df['type'].value_counts()
# Display the distribution
location_distribution

Geographical Visualization
import pandas as pd
import matplotlib.pyplot as plt
# Ensure that the latitude and longitude data are in numeric format
df['lat'] = pd.to_numeric(df['lat'], errors='coerce')
df['lon'] = pd.to_numeric(df['lon'], errors='coerce')
# Filter the dataframe for coordinates between 48 and 51 degrees longitude
filtered_df = df[(df['lon'] >= 48) & (df['lon'] <= 51)]
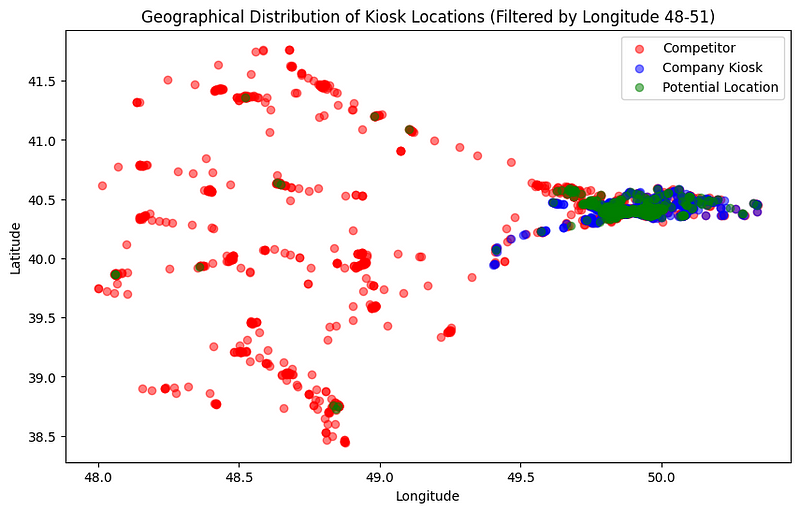
plt.figure(figsize=(10, 6))
# Plot each type with different colors within the filtered range
plt.scatter(filtered_df[filtered_df['type'] == 'competitor']['lon'], filtered_df[filtered_df['type'] == 'competitor']['lat'], color='red', label='Competitor', alpha=0.5)
plt.scatter(filtered_df[filtered_df['type'] == 'company']['lon'], filtered_df[filtered_df['type'] == 'company']['lat'], color='blue', label='Company Kiosk', alpha=0.5)
plt.scatter(filtered_df[filtered_df['type'] == 'potential']['lon'], filtered_df[filtered_df['type'] == 'potential']['lat'], color='green', label='Potential Location', alpha=0.5)
# Add title and legend
plt.title('Geographical Distribution of Kiosk Locations (Filtered by Longitude 48-51)')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.legend()
plt.show()
Optimizing Location Selection
import numpy as np
import pandas as pd
from scipy.spatial import cKDTree
import random
import matplotlib.pyplot as plt
# Set random seeds for reproducibility
np.random.seed(42)
random.seed(42)
# Load the CSV file
filtered_df = pd.read_csv('data/data.csv')
# Ensure that the latitude and longitude data are in numeric format
filtered_df['lat'] = pd.to_numeric(filtered_df['lat'], errors='coerce')
filtered_df['lon'] = pd.to_numeric(filtered_df['lon'], errors='coerce')
# Drop rows with invalid lat/lon values
filtered_df = filtered_df.dropna(subset=['lat', 'lon'])
# Extract latitude and longitude for competitors and company kiosks
competitor_coords = filtered_df[filtered_df['type'] == 'competitor'][['lat', 'lon']].values
company_coords = filtered_df[filtered_df['type'] == 'company'][['lat', 'lon']].values
# Build KD-Trees for fast nearest-neighbor lookup
competitor_tree = cKDTree(competitor_coords)
company_tree = cKDTree(company_coords)
# List to store final scores
final_scores = []
# Iterate through each potential location
for index, row in filtered_df[filtered_df['type'] == 'potential'].iterrows():
potential_loc = [row['lat'], row['lon']]
# Find the nearest competitor and company kiosk
_, nearest_competitor_dist = competitor_tree.query(potential_loc)
_, nearest_company_dist = company_tree.query(potential_loc)
# Calculate scores based on distances
score_competitor = nearest_competitor_dist # further is better
score_company = 1 / nearest_company_dist if nearest_company_dist > 0 else 0 # closer is better
# Calculate weighted score
weighted_score = (score_competitor * 0.6) + (score_company * 0.4)
# Append the score with the location data
final_scores.append((row['lat'], row['lon'], row['name'], row['company'], weighted_score))
# Convert the final scores into a DataFrame for easy viewing
scores_df_optimized = pd.DataFrame(final_scores, columns=['Latitude', 'Longitude', 'Location Name', 'Company', 'Weighted Score']).sort_values(by='Weighted Score', ascending=False)
# Select the top 3 results (highest scores)
top_3 = scores_df_optimized.head(3)
# Extract the specific columns for display
result_df = top_3[['Company', 'Location Name', 'Weighted Score']]
print(result_df)

Conclusion: Best Location Found
The analysis indicates that the optimal place for a new terminal is the Deniz Mall, recognized as a prime area in Baku, Azerbaijan. Furthermore, I seek to identify the nearest terminal operated by our company.
import numpy as np
import pandas as pd
from scipy.spatial import cKDTree
# Load the CSV file
filtered_df = pd.read_csv('data/data.csv')
# Ensure that the latitude and longitude data are in numeric format
filtered_df['lat'] = pd.to_numeric(filtered_df['lat'], errors='coerce')
filtered_df['lon'] = pd.to_numeric(filtered_df['lon'], errors='coerce')
# Drop rows with invalid lat/lon values
filtered_df = filtered_df.dropna(subset=['lat', 'lon'])
# Extract the location details for the potential location "Bravo D?niz Mall"
target_location = filtered_df[(filtered_df['name'] == 'Bravo D?niz Mall') & (filtered_df['company'] == 'bravo')].iloc[0]
# Extract latitude and longitude for company kiosks
company_coords = filtered_df[filtered_df['type'] == 'company'][['lat', 'lon']].values
# Build KD-Tree for company kiosks
company_tree = cKDTree(company_coords)
# Find the nearest company terminal
target_loc = [target_location['lat'], target_location['lon']]
distance_deg, nearest_company_idx = company_tree.query(target_loc)
# Convert distance from degrees to meters
distance_meters = distance_deg * 111000 # Approximate conversion for latitude
# Get the nearest company terminal details
nearest_terminal = filtered_df[(filtered_df['type'] == 'company')].iloc[nearest_company_idx]
# Display the nearest terminal details
print(f"Nearest terminal to '{target_location['name']}' ({target_location['company']}):")
print(f"Terminal Name: {nearest_terminal['name']}")
print(f"Distance: {distance_meters:.2f} meters")
# Save the result as a DataFrame (optional)
nearest_terminal_df = pd.DataFrame({
'Potential Location': [target_location['name']],
'Nearest Company Terminal': [nearest_terminal['name']],
'Distance (meters)': [distance_meters]
})

Thank you for collaborating on identifying the best site for your new terminal. Our analysis points to Bravo D?niz Mall as an outstanding option, given its high score, making it an excellent choice in Baku. Additionally, we’ve located the nearest existing terminal, just 1730.94 meters away, enhancing convenience further.
Should you have any further inquiries or require assistance, please don’t hesitate to contact me. Wishing you the best with your new location and continued success!